One may search inside the book at Amazon; it’s all part of its “Alexandria” project.
The system quite evidently uses optical character recognition to read the book pages, which are often visibly out of square when seen online. However, the OCR cannot handle uncommon ligatures.
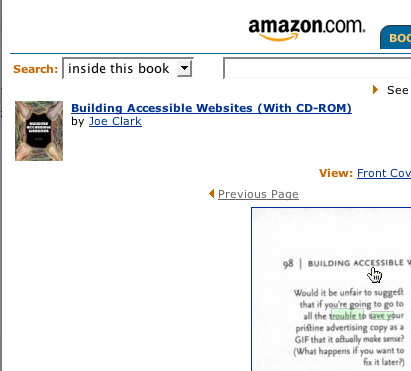
Page 98 of my book contains a photo cutline that reads as follows:
- Unencoded text (but with markup)
-
Would it be unfair to suggest that if you’re going to go to all the trouble to save your pristine advertising copy as a GIF that it actually make sense? (What happens if you want to fix it later?)
- Unicode text
-
Would it be unfair to suggest that if you’re going to go to all the trouble to save your pristine advertising copy as a GIF that it actually make sense? (What happens if you want to fix it later?)
- Text with entities
-
Would it be unfair to suggest that if you’re going to go to all the trouble to save your pristine advertising copy as a GIF that it actually make sense? (What happens if you want to fix it later?)
(Note that the ct ligature has no Unicode encoding, and, I am very testily informed by Michael Everson, never will. Note further that the fi ligature worked fine.)
And Amazon renders it thus (truncation theirs):
-

-
-
Would it be unfair to suggel that if you’re going to go to all the trouble to save your pri4tine advertising copy as a GIF that it aEtually make sense? (What happens if you want to fix it
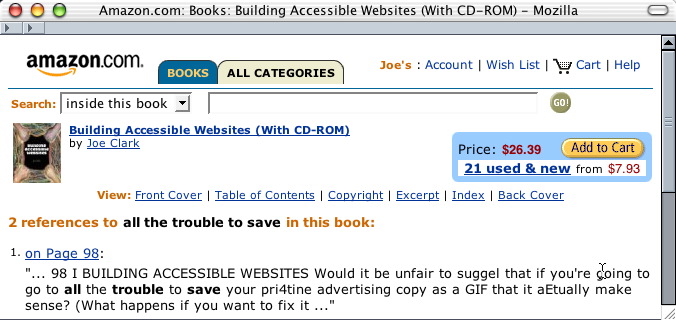
Got a wee bit of work to do there, I think.